A Oracle comprou a SUN e conseqüentemente o Java e o MySQL. Mais informações podem ser obtidas aqui. Que impactos esta aquisição causará sobre o PostgreSQL?
Ainda é muito cedo para ter certezas sobre este tema, mas ele certamente é bastante crítico para a área de banco de dados. A Oracle adquiriu nos últimos anos uma série de empresas e seus softwares de banco, dentre elas o Berkeley DB, que passaram a figurar entre as soluções desta empresa. As novas aquisições continuarão a ser livres e a serem aprimoradas? O suporte do java ao PostgreSQL estará ameaçado? O espaço para o PostgreSQL diminuirá ou será ampliado? Estas e outras questões permanecem em aberto.
Baseado nestas dúvidas tive a idéia de criar um tópico aberto. Peço que coloquem opiniões e links para reportagens sobre o impacto desta aquisição para a comunidade de banco de dados e particularmente para os usuários do PostgreSQL.
Atualização (13/05/2009): anexo link para posts sobre o assunto no site do Fernando Ike e do Telles.
terça-feira, 28 de abril de 2009
quinta-feira, 16 de abril de 2009
Versão 8.4: primeira release beta disponível!
O grupo de desenvolvimento do PostgreSQL anunciou que a primeira versão 8.4 BETA está disponível para download. A colaboração da comunidade nos testes é de vital importância para o diagnóstico e correção de quaisquer problemas na ferramenta. Esta versão não deve ser utilizada para aplicações corporativas, por ser menos estável que as releases padrão.
Testemos, critiquemos e participemos!!!
Mais informações em: http://www.postgresql.org/developer/beta.
Em breve apresentaremos um detalhamento das novas funcionalidades da versão 8.4 neste espaço.
Testemos, critiquemos e participemos!!!
Mais informações em: http://www.postgresql.org/developer/beta.
Em breve apresentaremos um detalhamento das novas funcionalidades da versão 8.4 neste espaço.
quarta-feira, 8 de abril de 2009
Fique Atualizado em PostgreSQL com o Addict-o-matic!!!
Ficar atualizado em tecnologias de hardware e software não é das tarefas mais fáceis. O site Addict-o-matic faz a coleta de uma série de notícias, posts em blogs, vídeos e imagens em uma série de fontes na rede. O resultado de uma pesquisa sobre o PostgreSQL não decepcionou.
Clique aqui para experimentar! Podem ser fornecidas várias opções de pesquisa, e o site funciona bem como agregador de informações.
A dica do site foi do blog da colunista Sandra Carvalho.
Clique aqui para experimentar! Podem ser fornecidas várias opções de pesquisa, e o site funciona bem como agregador de informações.
A dica do site foi do blog da colunista Sandra Carvalho.
sexta-feira, 3 de abril de 2009
Ano Bissexto no PostgreSQL!
Às vezes o mais difícil de fazer são coisas realmente simples. Os exemplo de código abaixo são implementações de uma rotina que calcula se um ano é bissexto ou não.
Segundo a Wikipedia, as regras do ano bissexto são poucas, mas não são triviais:
* São bissextos todos os anos múltiplos de 400, p.ex: 1600, 2000, 2400, 2800
* Não são bissextos todos os múltiplos de 100 e não de 400, p.ex: 1700, 1800, 1900, 2100, 2200, 2300, 2500...
* São bissextos todos os múltiplos de 4 e não múltiplos de 100, p.ex: 1996, 2004, 2008, 2012, 2016...
* Não são bissextos todos os demais anos.
Com base no que é apresentado neste post, peço que você que me responda três perguntas:
- Os dois exemplos abaixo estão corretos?
- Qual dos dois apresentaria alguma vantagem em relação ao outro? Ou são ambos equivalentes?
- É possível melhorar as implementações? De que formas?
As duas funções criadas retornam 1 se ano for bissexto, 0 se não for e 99 se for anterior a 1582, para anos acima de 1582.
Exemplo 1:
CREATE OR REPLACE FUNCTION ano_bissexto (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=0; --Inicialização
IF ($1%400=0) THEN
ret:=1; /*Bissexto*/
ELSE
IF ($1%4=0) AND ($1%100<>0) THEN
ret:=1; /*Bissexto*/
END IF;
END IF;
RETURN ret;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto(1600);
Exemplo 2:
CREATE OR REPLACE FUNCTION ano_bissexto_menor (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=$1; --Inicialização
IF (ret%100=0) THEN
ret:=ret/100;
END IF;
IF ret%4=0 THEN
RETURN 1; --Bissexto
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto_menor(1600);
Segundo a Wikipedia, as regras do ano bissexto são poucas, mas não são triviais:
* São bissextos todos os anos múltiplos de 400, p.ex: 1600, 2000, 2400, 2800
* Não são bissextos todos os múltiplos de 100 e não de 400, p.ex: 1700, 1800, 1900, 2100, 2200, 2300, 2500...
* São bissextos todos os múltiplos de 4 e não múltiplos de 100, p.ex: 1996, 2004, 2008, 2012, 2016...
* Não são bissextos todos os demais anos.
Com base no que é apresentado neste post, peço que você que me responda três perguntas:
- Os dois exemplos abaixo estão corretos?
- Qual dos dois apresentaria alguma vantagem em relação ao outro? Ou são ambos equivalentes?
- É possível melhorar as implementações? De que formas?
As duas funções criadas retornam 1 se ano for bissexto, 0 se não for e 99 se for anterior a 1582, para anos acima de 1582.
Exemplo 1:
CREATE OR REPLACE FUNCTION ano_bissexto (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=0; --Inicialização
IF ($1%400=0) THEN
ret:=1; /*Bissexto*/
ELSE
IF ($1%4=0) AND ($1%100<>0) THEN
ret:=1; /*Bissexto*/
END IF;
END IF;
RETURN ret;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto(1600);
Exemplo 2:
CREATE OR REPLACE FUNCTION ano_bissexto_menor (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=$1; --Inicialização
IF (ret%100=0) THEN
ret:=ret/100;
END IF;
IF ret%4=0 THEN
RETURN 1; --Bissexto
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto_menor(1600);
quinta-feira, 2 de abril de 2009
Enquete Encerrada: PostgreSQL é um Ótimo Nome para Banco de Dados!
A enquete que perguntava a respeito do nome do PostgreSQL foi encerrada, e foi considerado que o nome tradicional deve ser mantido por uma maioria esmagadora. Os nomes alternativos sugeridos não tiveram aceitação e a opção de outros nomes não foi acolhida. Abaixo, os dados:

| Opção | Votos | Percentual |
| Deve ser mantido. | 152 | 69,72 |
| Que tal PgDB? | 15 | 6,88 |
| Postgree seria melhor | 35 | 16,06 |
| Outro | 9 | 4,13 |
| Não sei. | 7 | 3,21 |
| Totais | 218 | 100 |
Concorda com o resultado? Discorda? Deixe seu comentário!

sexta-feira, 27 de março de 2009
Log com Arquivos CSV
Arquivos texto são muito utilizados em sistemas de informação. No entanto, sua manipulação automática muitas vezes é difícil por serem meios não estruturados de armazenamento de informações. O uso de arquivos CSV (Comma-Separated-Values - arquivos com valores separados por vírgula) facilita a utilização de arquivos texto para o armazenamento de dados. Um dos usos de arquivos CSV é no armazenamento do log de bancos de dados PostgreSQL, que passa a ser mais facilmente tratado por meio de planilhas eletrônicas, que apresentam os itens do log de forma tabular.
A utilização de log em arquivo CSV é muito simples, bastando se alterar o arquivo POSTGRESQL.CONF, alterando o parâmetro log_destination, e fazer o reload da configuração. Comente o valor anterior do parâmetro e coloque esta linha:
log_destination = 'csvlog'
A partir deste momento os arquivos de log criados serão do tipo CSV. Abaixo, uma imagem ilustrando como fica armazenado fisicamente o log:
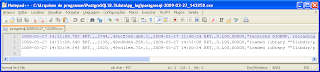
A utilização de log em arquivo CSV é muito simples, bastando se alterar o arquivo POSTGRESQL.CONF, alterando o parâmetro log_destination, e fazer o reload da configuração. Comente o valor anterior do parâmetro e coloque esta linha:
log_destination = 'csvlog'
A partir deste momento os arquivos de log criados serão do tipo CSV. Abaixo, uma imagem ilustrando como fica armazenado fisicamente o log:

segunda-feira, 16 de março de 2009
Que linguagem você utiliza com o PostgreSQL?
Que linguagem você utiliza com o PostgreSQL? Esta é a enquete atual do site do PostgreSQL. Participe!
www.postgresql.org/community
www.postgresql.org/community
quarta-feira, 11 de março de 2009
Possíveis Funcionalidades das Versões Futuras do PostgreSQL
Pouco se sabe ainda das novas funcionalidades a serem implementadas na versão 8.4 do PostgreSQL. Recentemente, uma apresentação recente de Bruce Momjian apresentou uma descrição de algumas das principais alterações em implementação. As funcionalidades prometem melhor desempenho e facilidade em certos tipos de consulta.
Algumas das principais alterações da versão 8.4 seriam:
- Column-Level Permissions - Permissões de acesso em por coluna.
- Windowing Functions: Sum and Rank - Ranqueamento de registros e somatório em uma sintaxe simples.
- WITH Queries: Simple and Recursive - sintaxe alternativa para a realização de consultas, inclusive permitindo recursividade.
- Parallel Restore of Dumps - Uso de threads para ganhar paralelismo na restauração de backups. Deve depender do sistema operacjional para funcionar.
- Visibility Maps Reduce Vacuum Overhead - Aprimoramento do desempenho das rotinas de Vacuum.
- No Need for Free-Space Map Configuration - Remoção de configurações dos arquivos de configuração.
- Default Values for Function Arguments - Funções com valores DEFAULT para retorno.
- Outras alterações, principalmente voltadas para o desempenho.
Confira as alterações segundo o texto original aqui.
Esta informação foi obtida no blog do Guedes.
Algumas das principais alterações da versão 8.4 seriam:
- Column-Level Permissions - Permissões de acesso em por coluna.
- Windowing Functions: Sum and Rank - Ranqueamento de registros e somatório em uma sintaxe simples.
- WITH Queries: Simple and Recursive - sintaxe alternativa para a realização de consultas, inclusive permitindo recursividade.
- Parallel Restore of Dumps - Uso de threads para ganhar paralelismo na restauração de backups. Deve depender do sistema operacjional para funcionar.
- Visibility Maps Reduce Vacuum Overhead - Aprimoramento do desempenho das rotinas de Vacuum.
- No Need for Free-Space Map Configuration - Remoção de configurações dos arquivos de configuração.
- Default Values for Function Arguments - Funções com valores DEFAULT para retorno.
- Outras alterações, principalmente voltadas para o desempenho.
Confira as alterações segundo o texto original aqui.
Esta informação foi obtida no blog do Guedes.
sexta-feira, 13 de fevereiro de 2009
Documentando Objetos no PostgreSQL
Onde guardar a documentação sobre os objetos do seu banco de dados? A importância a e grande quantidade de informação sobre tabelas, seus campos, índices e outros objetos faz com que essa questão ganhe importância. Um bom lugar para fazer esse registro é justamente o próprio banco de dados. No PostgreSQL é possível se comentar os objetos armazenados no banco, atualizar, remover e consultar essas informações, através do comando COMMENT.
O comando COMMENT armazena um comentário textual associado a um objeto do banco de dados. Sua sintaxe é relativamente simples:
A grande lista de tipos de objetos para os quais o comando pode criar comentários é bastante abrangente. Compreende tabelas, campos de tabelas, índices, tablespaces, esquemas, databases, tipos, funções, etc. Os comentários são armazenados em campos TEXT, que permitem documentações largamente detalhadas.
Os comentários são consultados por meio do utilitário PSQL e de algumas funções disponibilizadas pelo PostgreSQL (
create table starttest (col int);
create table starttest2 (col int);
2 - Definição de Comentários
COMMENT ON TABLE starttest IS 'Tabela do sistema SITP';
COMMENT ON TABLE starttest2 IS 'SITP - Modulo II';
3 - Remoção de Comentários
COMMENT ON TABLE starttest IS NULL;
1 - Recuperação de OID de objeto em PG_CLASS.
SELECT relname, relfilenode
FROM PG_CLASS
WHERE relname LIKE 'starttest%';
2 - Consulta dos commentários associados pelo OID.
SELECT obj_description(17173);
3 - Consulta dos comentários de todos os objetos de PG_CLASS.
SELECT obj_description(p.relfilenode), * from pg_class p;
4 - Consulta dos comentários de todos os objetos de PG_TYPE.
SELECT obj_description(p.typrelid), * from PG_TYPE p;
O uso do comando COMMENT para documentar objetos do banco é pouco difundido em parte pelo fato do mesmo ser pouco conhecido, não apresentar similares em alguns SGBDs e por não ser gerado por muitas das ferramentas do mercado, que armazenam estas informações em formato próprio, sem transferi-las ao SGBD.
Também existem questões de segurança, pois um usuário malicioso que tenha acesso ao banco pode recuperar os comentários sobre os seus objetos. No entanto, o interesse real dos invasores de bancos de dados se refere às informações armazenadas, e não à documentação dos bancos de dados.
Deve ser evitado armazenar qualquer informação crítica para a segurança com o comando COMMENT, tais como senhas, informações sobre criptografia e política de acesso utilizados, uma vez que não existem restrições de segurança para os comentários armazenados, isto é, qualquer usuário criado no SGBD visualiza todas as informações.
Os comentários são exportados ao se fazer um backup do banco com os utilitários do PostgreSQL.
O comando COMMENT armazena um comentário textual associado a um objeto do banco de dados. Sua sintaxe é relativamente simples:
COMMENT ON
{
TABLE object_name |
COLUMN table_name.column_name |
AGGREGATE agg_name (agg_type [, ...] ) |
CAST (sourcetype AS targettype) |
CONSTRAINT constraint_name ON table_name |
CONVERSION object_name |
DATABASE object_name |
DOMAIN object_name |
FUNCTION func_name ( [ [ argmode ] [ argname ] argtype [, ...] ] ) |
INDEX object_name |
LARGE OBJECT large_object_oid |
OPERATOR op (leftoperand_type, rightoperand_type) |
OPERATOR CLASS object_name USING index_method |
OPERATOR FAMILY object_name USING index_method |
[ PROCEDURAL ] LANGUAGE object_name |
ROLE object_name |
RULE rule_name ON table_name |
SCHEMA object_name |
SEQUENCE object_name |
TABLESPACE object_name |
TEXT SEARCH CONFIGURATION object_name |
TEXT SEARCH DICTIONARY object_name |
TEXT SEARCH PARSER object_name |
TEXT SEARCH TEMPLATE object_name |
TRIGGER trigger_name ON table_name |
TYPE object_name |
VIEW object_name
} IS 'text'
A grande lista de tipos de objetos para os quais o comando pode criar comentários é bastante abrangente. Compreende tabelas, campos de tabelas, índices, tablespaces, esquemas, databases, tipos, funções, etc. Os comentários são armazenados em campos TEXT, que permitem documentações largamente detalhadas.
Os comentários são consultados por meio do utilitário PSQL e de algumas funções disponibilizadas pelo PostgreSQL (
obj_description, col_description, and shobj_description).- Exemplos de Código - Criação de Comentário
create table starttest (col int);
create table starttest2 (col int);
2 - Definição de Comentários
COMMENT ON TABLE starttest IS 'Tabela do sistema SITP';
COMMENT ON TABLE starttest2 IS 'SITP - Modulo II';
3 - Remoção de Comentários
COMMENT ON TABLE starttest IS NULL;
- Exemplos de Código - Consulta de Comentários
1 - Recuperação de OID de objeto em PG_CLASS.
SELECT relname, relfilenode
FROM PG_CLASS
WHERE relname LIKE 'starttest%';
2 - Consulta dos commentários associados pelo OID.
SELECT obj_description(17173);
3 - Consulta dos comentários de todos os objetos de PG_CLASS.
SELECT obj_description(p.relfilenode), * from pg_class p;
4 - Consulta dos comentários de todos os objetos de PG_TYPE.
SELECT obj_description(p.typrelid), * from PG_TYPE p;
- Utilizaçao Prática
O uso do comando COMMENT para documentar objetos do banco é pouco difundido em parte pelo fato do mesmo ser pouco conhecido, não apresentar similares em alguns SGBDs e por não ser gerado por muitas das ferramentas do mercado, que armazenam estas informações em formato próprio, sem transferi-las ao SGBD.
Também existem questões de segurança, pois um usuário malicioso que tenha acesso ao banco pode recuperar os comentários sobre os seus objetos. No entanto, o interesse real dos invasores de bancos de dados se refere às informações armazenadas, e não à documentação dos bancos de dados.
Deve ser evitado armazenar qualquer informação crítica para a segurança com o comando COMMENT, tais como senhas, informações sobre criptografia e política de acesso utilizados, uma vez que não existem restrições de segurança para os comentários armazenados, isto é, qualquer usuário criado no SGBD visualiza todas as informações.
Os comentários são exportados ao se fazer um backup do banco com os utilitários do PostgreSQL.
quarta-feira, 28 de janeiro de 2009
Configuração Básica de Driver ODBC para PostgreSQL
Acesso a dados demanda um bom middleware. E a tecnologia ODBC - Open Database Connectivity, é uma opção bastante estável, disponível desde 1992. Por apresentar drivers para praticamente todos os bons SGBDs do mercado, muitas soluções são implementadas utilizando esta tecnologia.
O suporte às funcionalidades de um SGBD relacional e a grande disponibilidade de drivers são grandes pontos fortes deste middleware. Como problemas podem ser elencadas a falta de atualizações recentes, com defasagem em termos de novas funcionalidades oferecidas por outros componentes de acesso a dados e o fato de ser uma tecnologia proprietária.
Longe de esgotar este tópico, este post mostra uma configuração básica de ODBC para PostgreSQL, como a que foi utilizada para a utilização da ferramenta DbDesigner Fork.
* Etapa 1- Instalação
É sempre recomendável baixar a versão mais atualizada disponível, no site da comunidade PostgreSQL.ORG: http://www.postgresql.org/ftp/odbc/versions/
No nosso caso, a instalação será feita em uma máquina com Windows XP. Existem formas de utilizar o ODBC no Linux e no UNIX e meios de se fazer pontes envolvendo ODBC e JDBC, mas estas variações estão (bastante) fora do escopo deste post.
Descompacte o arquivo ZIP e execute o instalador. É sempre aconselhável ler antes o arquivo readme e se for uma atualização, pode ser disparado o arquivo upgrade.bat. Na instalação padrão um assistente relativamente simples se encarregará do processo sem que se precise fazer configurações complicadas.
 * Etapa 2 - Configuração
* Etapa 2 - Configuração
Após a instalação, abra o painel de controle do windows (Menu Iniciar/ Painel de Controle). Dispare a opção "Ferramentas administrativas" e depois selecione "Fontes de Dados (ODBC)".
Será aberta a tela "Administrador de Fonte de Dados ODBC". Nesta tela, selecione a aba "Drivers ODBC que estão instalados no sistema". Observe na imagem abaixo que foram instalados os drivers para PostgreSQL ANSI e UNICODE.

Para criar um data source, selecione a aba "Fonte de dados do usuário" e o botão "Adicionar". Aparecerá uma tela como a que está abaixo. Selecione o driver do PostgreSQL e confirme.
Em seguida, preencha os valores para o nome da fonte (Description), banco de dados para o qual aponta (Database), servidor em que está o banco de dados (Server), Porta de Comunicação (Port), usuário e senha. O servidor pode assumir os valores "localhost" ou um endereço IP. Utilize o botão TEST para verificar se os dados foram devidamente fornecidos e se a conexão pode ser feita e a opção SAVE para gravar a configuração do driver.
A opção "Configurar" permite a alteração de uma fonte de dados do usuário, abrindo a tela abaixo. Os botões Datasource, Global e Manage DSN estão fora do escopo deste post.

Após fazer a instalação, a nova fonte de dados do usuário aparece na lista, podendo ser utilizada por várias aplicações compatíveis com o ODBC.

Mais informações sobre ODBC podem ser obtidas nestas fontes:
- Na Wikipedia
- Site Easysoft, com informações sobre ODBC em UNIX e Linux
O suporte às funcionalidades de um SGBD relacional e a grande disponibilidade de drivers são grandes pontos fortes deste middleware. Como problemas podem ser elencadas a falta de atualizações recentes, com defasagem em termos de novas funcionalidades oferecidas por outros componentes de acesso a dados e o fato de ser uma tecnologia proprietária.
Longe de esgotar este tópico, este post mostra uma configuração básica de ODBC para PostgreSQL, como a que foi utilizada para a utilização da ferramenta DbDesigner Fork.
* Etapa 1- Instalação
É sempre recomendável baixar a versão mais atualizada disponível, no site da comunidade PostgreSQL.ORG: http://www.postgresql.org/ftp/odbc/versions/
No nosso caso, a instalação será feita em uma máquina com Windows XP. Existem formas de utilizar o ODBC no Linux e no UNIX e meios de se fazer pontes envolvendo ODBC e JDBC, mas estas variações estão (bastante) fora do escopo deste post.
Descompacte o arquivo ZIP e execute o instalador. É sempre aconselhável ler antes o arquivo readme e se for uma atualização, pode ser disparado o arquivo upgrade.bat. Na instalação padrão um assistente relativamente simples se encarregará do processo sem que se precise fazer configurações complicadas.
 * Etapa 2 - Configuração
* Etapa 2 - ConfiguraçãoApós a instalação, abra o painel de controle do windows (Menu Iniciar/ Painel de Controle). Dispare a opção "Ferramentas administrativas" e depois selecione "Fontes de Dados (ODBC)".
Será aberta a tela "Administrador de Fonte de Dados ODBC". Nesta tela, selecione a aba "Drivers ODBC que estão instalados no sistema". Observe na imagem abaixo que foram instalados os drivers para PostgreSQL ANSI e UNICODE.

Para criar um data source, selecione a aba "Fonte de dados do usuário" e o botão "Adicionar". Aparecerá uma tela como a que está abaixo. Selecione o driver do PostgreSQL e confirme.
Em seguida, preencha os valores para o nome da fonte (Description), banco de dados para o qual aponta (Database), servidor em que está o banco de dados (Server), Porta de Comunicação (Port), usuário e senha. O servidor pode assumir os valores "localhost" ou um endereço IP. Utilize o botão TEST para verificar se os dados foram devidamente fornecidos e se a conexão pode ser feita e a opção SAVE para gravar a configuração do driver.
A opção "Configurar" permite a alteração de uma fonte de dados do usuário, abrindo a tela abaixo. Os botões Datasource, Global e Manage DSN estão fora do escopo deste post.

Após fazer a instalação, a nova fonte de dados do usuário aparece na lista, podendo ser utilizada por várias aplicações compatíveis com o ODBC.

Mais informações sobre ODBC podem ser obtidas nestas fontes:
- Na Wikipedia
- Site Easysoft, com informações sobre ODBC em UNIX e Linux
quarta-feira, 14 de janeiro de 2009
Power Architect - Ótima Ferramenta Livre!!!
Falar de ferramentas de banco de dados geralmente implica em destacar suas limitações. Uma exceção é o Power Architect, que apresenta boas e úteis funcionalidades para o desenvolvimento de aplicações que tenham um certo grau de complexidade. É uma ferramenta livre e de código aberto, cujo download pode ser feito aqui.
Não é exclusiva para o PostgreSQL, podendo também ser utilizada em projetos com Oracle, SQL Server, MySQL, Derby e HSQLDB. O desenvolvimento é pago por taxa de suporte premium de 199 dólares ao ano, o que é relativamente baixo em se falando de ferramentas de base de dados.
As principais funcionalidades são:
Alguns problemas ou desvantagens foram constatados. Falta suporte a visões, triggers, restrições tipo check e stored procedures, recursos importantes para o projeto de bancos de dados de maior complexidade. Outros problemas menores constatados foram: falta Suporte a trabalho em grupos, ausência de Controle de versões e falta de interface WEB.
Abaixo, algumas telas capturadas:



* Avaliação Geral
A ferramenta é superior ao DBDesigner e pode ser utilizada para projetos que não sejam de pequeno porte. Apresentou poucos bugs nos testes realizados. No entanto, as desvantagens apesar de poucas são significativas.
Não é exclusiva para o PostgreSQL, podendo também ser utilizada em projetos com Oracle, SQL Server, MySQL, Derby e HSQLDB. O desenvolvimento é pago por taxa de suporte premium de 199 dólares ao ano, o que é relativamente baixo em se falando de ferramentas de base de dados.
As principais funcionalidades são:
- Boa interface visual com diagramas de ER e OLAP
- Acesso a bancos de dados via JDBC
- Conexão a múltiplas fntes de dados ao mesmo tempo
- Comparação de modelos de dados com identificação de diferenças e geração de scripts de sincronização
- Suporte a "Drag-and-drop" de tabelas de um modelo para o playpen (diagrama)
- Geração de banco de dados através do projeto (Forward-engineers)
- Engenharia reversa para a construção dos projetos
- Salvamento da estrutura de dados em um projeto que pode ser trabalhado remotemante
- Dados do projeto armazenados em um formato XML de fácil navegação
- Licença livre GPL (version 3)
- Suporte rudimentar a ETL - Extração, Transformação e Carga de Dados
- Suporte a esquemas OLAP para projeto de Data Warehouses
Alguns problemas ou desvantagens foram constatados. Falta suporte a visões, triggers, restrições tipo check e stored procedures, recursos importantes para o projeto de bancos de dados de maior complexidade. Outros problemas menores constatados foram: falta Suporte a trabalho em grupos, ausência de Controle de versões e falta de interface WEB.
Abaixo, algumas telas capturadas:
- Tela de conexão a banco de dados PostgreSQL, tendo ao fundo uma visão geral da ferramenta.

- Parâmetros para a comparação entre bancos de dados

- Tela de resultado da comparação entre bancos de dados.

* Avaliação Geral
A ferramenta é superior ao DBDesigner e pode ser utilizada para projetos que não sejam de pequeno porte. Apresentou poucos bugs nos testes realizados. No entanto, as desvantagens apesar de poucas são significativas.
segunda-feira, 12 de janeiro de 2009
PostgreSQL: primeira release de 2009!!!
A equipe do PostgreSQL lançou a primeira release de 2009, apresentando uma versão instável que não deve ser utilizada para ambientes de produção, que consiste basicamente em uma visão snapshot das atualizações feitas no desenvolvimento do banco. O instalador pode ser baixado aqui. A documentação desta versão está disponível aqui, mas não conta por exemplo com uma seção "release notes" apesar de apreentar no título referência à versão 8.4.
É uma boa opção para desenvolvedores e testadores que querem se antecipar às novas funcionalidades da versão 8.4 que estão em desenvolvimento ou colaborar nos testes.
Acredita-se que no primeiro semestre serão lançadas as primeiras versões de teste para a nova release 8.4 deste SGBD.
É uma boa opção para desenvolvedores e testadores que querem se antecipar às novas funcionalidades da versão 8.4 que estão em desenvolvimento ou colaborar nos testes.
Acredita-se que no primeiro semestre serão lançadas as primeiras versões de teste para a nova release 8.4 deste SGBD.
Assinar:
Postagens (Atom)