A popularidade de uma ferramenta não garante a sua qualidade, mas é um bom indicador de sua aceitação no mercado. O site DB-ENGINES criou um ranking de SGBDs, utilizando uma metodologia bem estruturada que leva em conta menções em sites, buscas e ofertas de trabalho, entre outros critérios. A pontuação é atualizada mensalmente.
Ver o PostgreSQL em quarto lugar no ranking do mundo (03/2013), me surpreendeu positivamente. Imaginava que em certos lugares, como o nosso Brasil, ele seria bem colocado, mas não achei que essa aceitação fosse mundial!
O link se encontra abaixo:
- http://db-engines.com/en/ranking
Faltam detalhes como rankings por critério utilizado, fornecendo informações sobre, por exemplo, ofertas de emprego por banco de dados e região, mas acho que o é uma boa curiosidade que traz alguma informação nova. Pequei a dica deste link no blog Papo SQL.
quarta-feira, 27 de março de 2013
terça-feira, 26 de março de 2013
PgDay Ceará 2013: Site Oficial no ar
O site oficial do PgDAy Ceará 2013 está no ar, com links para inscrições e para a chamada de trabalhos, que ainda está aberta.
Peço a divulgação entre os possíveis interessados e saliento que a participação de todos é muito bem vinda!
PgDay Ceará 2013: Primeiros Palestrantes Confirmados!

Os primeiros palestrantes já foram confirmados no PgDay Ceará 2013. Ainda existe espaço na grade de palestras, então você está convidado a submeter sua apresentação:

- Fábio Telles Rodriguez
Palestrante nacionalmente conhecido, atua em como DBA Oracle, MySQL e PostgreSQL. É sócio fundador da Timbira, empresa especializada em bancos de dados PostgreSQL, migração entre bancos de dados, alta disponibilidade, ajustes de desempenho e treinamento. Colaborou nos projetos DebianZine, PSL-ABCD, Xoops e PostgreSQL.
Referências:
- http://savepoint.blog.br/
- http://www.timbira.com.br/timbira

- Nabucodonosor Coutinho
DBA de banco de dados PostgreSQL e Oracle. Palestrante e colaborador das comunidades PostgreSQL e Python. Sócio da Mondrian tecnologia, empresa especialista em banco de dados, consultoria e desenvolvimento. Atuou em grandes projetos de migração de bases de dados Oracle e SQLServer para PostgreSQL e na administração de Redes e Servidores Linux (RedHat, Fedora, Debian). Como gerente de projetos e desenvolvedor implementou sistemas baseados em Ruby On Rails, Java, Python, Cold Fusion, PHP, Perl e C#.
Referências:
- www.mondriantecnologia.com
- Cláudio Leopoldino
Analista de desenvolvimento de software do SERPRO e professor da UNICHRISTUS. Utiliza o PostgreSQL como ferramenta de ensino de Banco de Dados, atuando como articulista, blogueiro e palestrante em eventos de software livre e banco de dados.
Referências:
- http://postgresqlbr.blogspot.com.br/
Chamada de Trabalhos
O site da chamada de trabalhos ainda não está no ar, mas a submissão de palestras já pode ser feita diretamente para o e-mail claudiob_br@yahoo.com.br. Podem ser submetidas palestras técnicas e de casos de utilização do postgresql.
O correio enviado deve conter os seguintes dados:
- Nome Completo - Obrigatório para identificar o palestrante
- E-mail - Obrigatório para enviarmos lembretes aos palestrantes antes do evento.
- Telefone(s) de Contato - Obrigatório.
- Resumo da Palestra - Obrigatório. Resumo do conteúdo da palestra em uma página de texto.
- Instituição de Origem. - Obrigatório.
quinta-feira, 21 de março de 2013
DtSQL: Ferramenta Front-End para Banco de Dados
A procura por ferramentas que realmente aumentem a produtividade continua. O DtSQL apresenta um bom conjunto de funcionalidades e é compatível com o PostgreSQL e mais de 20 outros SGBDs. O DtSQL foi tornado livre em 2013, e tem sofrido atualizações recentemente, o que é um ponto positivo. Está disponível para Windows, Mac OS, Linux e UNIX.

Abaixo, coloco algumas informações, sobre os recursos oferecidos, com base na versão de março deste ano:
* Interface Gráfica Simples
- A interface gráfica é simples, mas parece bastante com outras já bastante conhecidas, como a do PgAdmin e a do Squirrel. Ao mesmo que isso facilita a utilização, deixa a impressão de que poderia agregar mais inovação e valor à ferramenta.

No entanto a interface não é perfeita. Para criar e executar comandos no editor de texto, deve-se clicar no banco de dados ou em um objeto (tabela ou visão). Demorei para descobrir este recurso, então creio que a interface não seja tão intuitiva quanto poderia.

* Assistentes
- Tarefas como a criação de tabelas, visões, índices e outros objetos são automatizadas por maio de assistentes que facilitam o trabalho.

* Query Builder (Confuso)
- Não posso dizer que gostei do Query Builder. Achei confuso e complicado. Mas recomendo que seja testado, pois pode ser exatamente o que você procura.

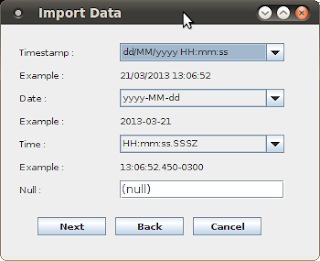
* Exportação/ Importação de Dados
- A exportação é a melhor feature da ferramenta. Assistentes permitem a exportação e importação em poucos cliques.
Não percebi bugs ou outros problemas no processo, mas recomendo testes para uso em bancos de dados de maiores proporções.





* Considerações Finais
A primeira impressão foi positiva, embora eu prefira soluções como o Squirrel. Creio que pode ser utilizada como front-end. Destaco os pontos positivos:
- Assistentes
- Disponibilidade para vários sistemas operacionais
- Conectividade com Múltiplos Bancos de Dados
- Recursos para importar/ exportar dados. Esta funcionalidade foi a que achei mais promissora.
- Atualizações recentes, indicando que a ferramenta não está parada.
Pontos negativos:
- Query builder confuso.
- Falta de recursos mais avançados como navegação gráfica nos dados, engenharia reversa, diagramação, monitoramento, etc.
- O código da ferramenta aparentemente não foi aberto.
- É mantida por uma empresa, não por uma comunidade, gerando dúvidas sobre o futuro da ferramenta.
Teste e me dê sua opinião!
Abaixo, coloco algumas informações, sobre os recursos oferecidos, com base na versão de março deste ano:
* Interface Gráfica Simples
- A interface gráfica é simples, mas parece bastante com outras já bastante conhecidas, como a do PgAdmin e a do Squirrel. Ao mesmo que isso facilita a utilização, deixa a impressão de que poderia agregar mais inovação e valor à ferramenta.

No entanto a interface não é perfeita. Para criar e executar comandos no editor de texto, deve-se clicar no banco de dados ou em um objeto (tabela ou visão). Demorei para descobrir este recurso, então creio que a interface não seja tão intuitiva quanto poderia.

* Assistentes
- Tarefas como a criação de tabelas, visões, índices e outros objetos são automatizadas por maio de assistentes que facilitam o trabalho.

* Query Builder (Confuso)
- Não posso dizer que gostei do Query Builder. Achei confuso e complicado. Mas recomendo que seja testado, pois pode ser exatamente o que você procura.

* Exportação/ Importação de Dados
- A exportação é a melhor feature da ferramenta. Assistentes permitem a exportação e importação em poucos cliques.
Não percebi bugs ou outros problemas no processo, mas recomendo testes para uso em bancos de dados de maiores proporções.
Exportação: Seleção de tabela a ser exportada.

Exportação: Parâmetros
Importação: Definição de Tabela para receber os dados

Importação: Parâmetros

Importação: Arquivo com dados a importar

Importação: Sumário
* Considerações Finais
A primeira impressão foi positiva, embora eu prefira soluções como o Squirrel. Creio que pode ser utilizada como front-end. Destaco os pontos positivos:
- Assistentes
- Disponibilidade para vários sistemas operacionais
- Conectividade com Múltiplos Bancos de Dados
- Recursos para importar/ exportar dados. Esta funcionalidade foi a que achei mais promissora.
- Atualizações recentes, indicando que a ferramenta não está parada.
Pontos negativos:
- Query builder confuso.
- Falta de recursos mais avançados como navegação gráfica nos dados, engenharia reversa, diagramação, monitoramento, etc.
- O código da ferramenta aparentemente não foi aberto.
- É mantida por uma empresa, não por uma comunidade, gerando dúvidas sobre o futuro da ferramenta.
Teste e me dê sua opinião!
quinta-feira, 14 de março de 2013
Imagem de Divulgação do PgDay Ceará 2013!
Esta é a imagem de divulgação do PgDay Ceará 2013. Pode ser divulgada livremente. O evento está definido para o dia 03 de maio, no centro universitário UNICHRISTUS, em Fortaleza-CE.
A chamada de trabalhos está em andamento e se encerrará assim que a grade de palestras estiver definida. Mais informações aqui.
As inscrições ainda não se iniciaram, mas nos próximos dias o site estará disponível.

A chamada de trabalhos está em andamento e se encerrará assim que a grade de palestras estiver definida. Mais informações aqui.
As inscrições ainda não se iniciaram, mas nos próximos dias o site estará disponível.

terça-feira, 12 de março de 2013
O PgDay Ceará Será Dia 03 de Maio!

O PgDay do Ceará foi oficialmente anunciado para o dia 03 de maio, uma sexta-feira. Trata-se de uma iniciativa do curso de Sistemas de Informacao da UNICHRISTUS. O evento visa explorar o banco de dados PostgreSQL e as tecnologias a
ele associadas, e ao mesmo tempo:
- Promover as boas praticas de utilização de bancos de dados, relacionadas ao PostgreSQL;
- Divulgar casos reais de aplicação desta tecnologia;
- Fomentar a exploração de recursos básicos, intermediários e avançados desta ferramenta;
- Contribuir efetivamente para o aprimoramento da área de tecnologia da informação da região;
- Permitir o intercambio dos alunos de sistemas de informação da Unichristus com profissionais de outras instituições.

A edição cearense deste evento
consistirá de uma sequência de palestras sobre o tema, apresentando uma
mesa de debates no seu encerramento. A chamada de trabalhos para a
submissão de palestras já está em andamento e as inscrições gratuitas
para alunos da Unichristus, profissionais, empresários, membros de ONGs e
acadêmicos de outras instituições poderão ser feitas no sítio da
faculdade em breve.
Atividades previstas:
- 14:00 – 14:30 - Recepção de participantes e conferencistas
- 14:30 – 17:15 – Palestras 1, 2 e 3
- 17:15h – 18:30h – Intervalo
- 18:30h – 21:15h – Palestras 4, 5 e 6
- 21:15h – 21:45h – Debate
- 22:00 - Encerramento
O site da chamada de trabalhos ainda não está no ar, mas a submissão de palestras já pode ser feita diretamente para o e-mail claudiob_br@yahoo.com.br. Podem ser submetidas palestras técnicas e de casos de utilização do postgresql. O correio enviado deve conter os seguintes dados:
- Nome Completo - Obrigatório para identificar o palestrante
- E-mail - Obrigatório para enviarmos lembretes aos palestrantes antes do evento.
- Telefone(s) de Contato - Obrigatório.
- Resumo da Palestra - Obrigatório. Resumo do conteúdo da palestra em uma página de texto.
- Instituição de Origem. - Obrigatório.
segunda-feira, 11 de março de 2013
Edição de SQL e Funções no PSQL
O psql é a principal interface dos desenvolvedores com o PostgreSQL. No entanto, editar códigos no psql pode ser uma tarefa onerosa. As consultas e funções podem ser extensas e o trabalho se tornar cansativo e improdutivo. Existem algumas opções que podem ajudar a trabalhar melhor com os códigos, sem precisar sair do PSQL, que abordamos resumidamente aqui.
- Executando arquivos TXT salvos previamente.
A maneira que mais utilizo para trabalhar com funções e SQL é executar arquivos txt salvos previamente. Gosto de ter scripts para as necessidades básicas em seus respectivos lugares, que possam ser reutilizados, e tem sido bem útil trabalhar desta forma. Edite o seu SQL no editor que achar melhor e salve-o. Para executa-lo, utilize a sintaxe:
\i (nome do arquivo como código SQL)
- Editar código SQL usando o Editor Padrão
Neste caso, o sistema abre o editor padrão definido para o postgresql. Caso não exista um editor definido, o postgres perguntará, dentre os disponíveis, qual você deseja utilizar. No meu caso, utilizo o nano (http://www.nano-editor.org/). É um editor bem simples e fácil de usar, que apresenta boas teclas de atalho.
Digite:
\e (ou \edit)
O sistema abre a tela do editor para inserir e editar seu texto, permitindo rolar as páginas e manter o SQL sem problemas. É possível salvar o script para reutilização. Para apenas executar, sem salvar, basta sair do editor. No caso do NANO, teclando CONTROL+X.

- Editar nova função no editor.
Ao se digitar \ef, o psql abre o Editor predeterminado, apresentando um "esqueleto de função" para edição. Basta sair teclando CONTROL+X para criar a função.
 - Editar função existente
- Editar função existente
Neste caso, utilize a sintaxe:
\ef (nome da função a editar)
Se você esqueceu o nome das funções que deseja editar, pode adaptar a consulta abaixo para descobrir.
SELECT proname, pronamespace, proowner FROM PG_PROC;
Agora é editar seus scripts, consultas e funções de dentro do psql!
OOPS! Alterando o Editor Padrão!
Já ia me esquecendo! Altere o editor padrão utilizando a sintaxe abaixo:
\set PSQL_EDITOR
- Executando arquivos TXT salvos previamente.
A maneira que mais utilizo para trabalhar com funções e SQL é executar arquivos txt salvos previamente. Gosto de ter scripts para as necessidades básicas em seus respectivos lugares, que possam ser reutilizados, e tem sido bem útil trabalhar desta forma. Edite o seu SQL no editor que achar melhor e salve-o. Para executa-lo, utilize a sintaxe:
\i (nome do arquivo como código SQL)
- Editar código SQL usando o Editor Padrão
Neste caso, o sistema abre o editor padrão definido para o postgresql. Caso não exista um editor definido, o postgres perguntará, dentre os disponíveis, qual você deseja utilizar. No meu caso, utilizo o nano (http://www.nano-editor.org/). É um editor bem simples e fácil de usar, que apresenta boas teclas de atalho.
Digite:

\e (ou \edit)
O sistema abre a tela do editor para inserir e editar seu texto, permitindo rolar as páginas e manter o SQL sem problemas. É possível salvar o script para reutilização. Para apenas executar, sem salvar, basta sair do editor. No caso do NANO, teclando CONTROL+X.

Ao se digitar \ef, o psql abre o Editor predeterminado, apresentando um "esqueleto de função" para edição. Basta sair teclando CONTROL+X para criar a função.

Neste caso, utilize a sintaxe:
\ef (nome da função a editar)
Se você esqueceu o nome das funções que deseja editar, pode adaptar a consulta abaixo para descobrir.

SELECT proname, pronamespace, proowner FROM PG_PROC;
Agora é editar seus scripts, consultas e funções de dentro do psql!
OOPS! Alterando o Editor Padrão!
Já ia me esquecendo! Altere o editor padrão utilizando a sintaxe abaixo:
\set PSQL_EDITOR
quinta-feira, 14 de fevereiro de 2013
Ajude e Participe da PgBr 2013!
Colabore na divulgação e submeta sua palestra para o maior evento de PostgreSQL do Brasil! Abaixo, coloco os banners oficiais.
Você é livre para divulgar da forma que puder! Avise palestrantes em potencial!


Você é livre para divulgar da forma que puder! Avise palestrantes em potencial!
Banner 1
Banner 2
quarta-feira, 6 de fevereiro de 2013
Produza Sequências Com a Função Generate_Series()!
A geração de séries numéricas e temporais tem diversas aplicações em bancos de dados. A produção de uma sequência de inteiros pode ser de grande valia para solucionar vários tipos de problemas, enquanto que uma lista de datas que seja produzida pode permitir o agendamento de tarefas, por exemplo. A função generate_series, implementada pelo postgres, permite a geração de diversas séries sem a necessidade de construção de programas ou funções iterativas, o que economiza esforço de programação.

A função generate_series assume três grandes formas:
- generate_series(valor inicial, valor final) - Gera uma série numérica de valores, partindo do valor inicial ao final, utilizando como incremento o valor 1;
- generate_series(valor inicial, valor final, incremento) - Gera uma série de valores, partindo do valor inicial ao final, utilizando como incremento o valor parametrizado. Produz uma progressão aritmética;
- generate_series(valor inicial, valor final, incremento do tipo intervalar) - Gera uma série temporal de valores, partindo do valor inicial ao final, ambos do tipo timestamp, utilizando como incremento o valor parametrizado.
Abaixo comento algumas das possibilidades oferecidas por estas funções:
* Sequências Simples
Abaixo, sequências numéricas simples que utilizam o incremento 1.
- Sequência simples.
postgres=# SELECT generate_series(1,3);
generate_series
-----------------
1
2
3
(3 registros)
- Sequência simulando incremento de 3 unidades.
postgres=# SELECT generate_series(1,5)*3-2 AS TRIPLO;
triplo
--------
1
4
7
10
13
(5 registros)- Sequência com incremento fracionário.
postgres=# SELECT (generate_series(1,5)*1.0)/2 AS FRACIONARIO;
fracionario
------------------------
0.50000000000000000000
1.00000000000000000000
1.5000000000000000
2.0000000000000000
2.5000000000000000
(5 registros)
- Sequência com valores repetidos, utilizando o operador de resto da divisão.
postgres=# SELECT generate_series(1,10)%5 AS REPETIDO;
repetido
----------
1
2
3
4
0
1 (REPETIÇÕES)
2
3
4
0
(10 registros)
* Sequências Com Incremento Explícito.
- Incremento 1, fornecido.
postgres=# SELECT generate_series(1,5,1);
generate_series
-----------------
1
2
3
4
5
(5 registros)
- Incremento 2, fornecido. Observe que se o valor máximo é atingido, a sequência é interrompida.
postgres=# SELECT generate_series(1,5,2);
generate_series
-----------------
1
3
5
(3 registros)
- Sequência com incremento decrescente.
postgres=# SELECT generate_series(5,1,-1);
generate_series
-----------------
5
4
3
2
1
(5 registros)
* Sequências Temporais.
Exigem um pouco mais de abstração por envolverem intervalos de tempo, mas não são necessariamente complexas. Abaixo elenco alguns exemplos elementares.
- Utilizando timestamps com a sintaxe mais básica.
postgres=# SELECT generate_series('2013-02-06 12:00'::timestamp,
postgres(# '2013-02-08 12:00'::timestamp,
postgres(# '1 day');
generate_series
---------------------
2013-02-06 12:00:00
2013-02-07 12:00:00
2013-02-08 12:00:00
(3 registros)
- Utilizando current_timestamp.
postgres=# SELECT generate_series(current_timestamp,
postgres(# current_timestamp + '5 days',
postgres(# '1 day');
generate_series
-------------------------------
2013-02-06 09:35:31.343344-03
2013-02-07 09:35:31.343344-03
2013-02-08 09:35:31.343344-03
2013-02-09 09:35:31.343344-03
2013-02-10 09:35:31.343344-03
2013-02-11 09:35:31.343344-03
(6 registros)
- Utilizando incremento de algumas horas.
postgres=# SELECT generate_series(current_timestamp,
postgres(# current_timestamp + '1 day',
postgres(# '8 hours');
generate_series
-------------------------------
2013-02-06 09:41:29.799331-03
2013-02-06 17:41:29.799331-03
2013-02-07 01:41:29.799331-03
2013-02-07 09:41:29.799331-03
(4 registros)
- Utilizando incremento decrescente.
postgres=# SELECT generate_series(current_timestamp + '5 days',
postgres(# current_timestamp,
postgres(# '-1 day');
generate_series
-------------------------------
2013-02-11 09:48:26.540137-03
2013-02-10 09:48:26.540137-03
2013-02-09 09:48:26.540137-03
2013-02-08 09:48:26.540137-03
2013-02-07 09:48:26.540137-03
2013-02-06 09:48:26.540137-03
(6 registros)
* Considerações Finais
A função generate_series() permite a economia de tempo e flexibilidade na geração de séries numéricas e temporais, produzindo um resultado legível e de fácil utilização. Não são a única forma de se gerar estes dados no postgres, e afeta a portabilidade de banco de dados, mas é um recurso importante a ser considerado pelos desenvolvedores.

Exemplos de sequências numéricas.
A função generate_series assume três grandes formas:
- generate_series(valor inicial, valor final) - Gera uma série numérica de valores, partindo do valor inicial ao final, utilizando como incremento o valor 1;
- generate_series(valor inicial, valor final, incremento) - Gera uma série de valores, partindo do valor inicial ao final, utilizando como incremento o valor parametrizado. Produz uma progressão aritmética;
- generate_series(valor inicial, valor final, incremento do tipo intervalar) - Gera uma série temporal de valores, partindo do valor inicial ao final, ambos do tipo timestamp, utilizando como incremento o valor parametrizado.
Abaixo comento algumas das possibilidades oferecidas por estas funções:
* Sequências Simples
Abaixo, sequências numéricas simples que utilizam o incremento 1.
- Sequência simples.
postgres=# SELECT generate_series(1,3);
generate_series
-----------------
1
2
3
(3 registros)
- Sequência simulando incremento de 3 unidades.
postgres=# SELECT generate_series(1,5)*3-2 AS TRIPLO;
triplo
--------
1
4
7
10
13
(5 registros)- Sequência com incremento fracionário.
postgres=# SELECT (generate_series(1,5)*1.0)/2 AS FRACIONARIO;
fracionario
------------------------
0.50000000000000000000
1.00000000000000000000
1.5000000000000000
2.0000000000000000
2.5000000000000000
(5 registros)
- Sequência com valores repetidos, utilizando o operador de resto da divisão.
postgres=# SELECT generate_series(1,10)%5 AS REPETIDO;
repetido
----------
1
2
3
4
0
1 (REPETIÇÕES)
2
3
4
0
(10 registros)
* Sequências Com Incremento Explícito.
- Incremento 1, fornecido.
postgres=# SELECT generate_series(1,5,1);
generate_series
-----------------
1
2
3
4
5
(5 registros)
- Incremento 2, fornecido. Observe que se o valor máximo é atingido, a sequência é interrompida.
postgres=# SELECT generate_series(1,5,2);
generate_series
-----------------
1
3
5
(3 registros)
- Sequência com incremento decrescente.
postgres=# SELECT generate_series(5,1,-1);
generate_series
-----------------
5
4
3
2
1
(5 registros)
* Sequências Temporais.
Exigem um pouco mais de abstração por envolverem intervalos de tempo, mas não são necessariamente complexas. Abaixo elenco alguns exemplos elementares.
- Utilizando timestamps com a sintaxe mais básica.
postgres=# SELECT generate_series('2013-02-06 12:00'::timestamp,
postgres(# '2013-02-08 12:00'::timestamp,
postgres(# '1 day');
generate_series
---------------------
2013-02-06 12:00:00
2013-02-07 12:00:00
2013-02-08 12:00:00
(3 registros)
- Utilizando current_timestamp.
postgres=# SELECT generate_series(current_timestamp,
postgres(# current_timestamp + '5 days',
postgres(# '1 day');
generate_series
-------------------------------
2013-02-06 09:35:31.343344-03
2013-02-07 09:35:31.343344-03
2013-02-08 09:35:31.343344-03
2013-02-09 09:35:31.343344-03
2013-02-10 09:35:31.343344-03
2013-02-11 09:35:31.343344-03
(6 registros)
- Utilizando incremento de algumas horas.
postgres=# SELECT generate_series(current_timestamp,
postgres(# current_timestamp + '1 day',
postgres(# '8 hours');
generate_series
-------------------------------
2013-02-06 09:41:29.799331-03
2013-02-06 17:41:29.799331-03
2013-02-07 01:41:29.799331-03
2013-02-07 09:41:29.799331-03
(4 registros)
- Utilizando incremento decrescente.
postgres=# SELECT generate_series(current_timestamp + '5 days',
postgres(# current_timestamp,
postgres(# '-1 day');
generate_series
-------------------------------
2013-02-11 09:48:26.540137-03
2013-02-10 09:48:26.540137-03
2013-02-09 09:48:26.540137-03
2013-02-08 09:48:26.540137-03
2013-02-07 09:48:26.540137-03
2013-02-06 09:48:26.540137-03
(6 registros)
* Considerações Finais
A função generate_series() permite a economia de tempo e flexibilidade na geração de séries numéricas e temporais, produzindo um resultado legível e de fácil utilização. Não são a única forma de se gerar estes dados no postgres, e afeta a portabilidade de banco de dados, mas é um recurso importante a ser considerado pelos desenvolvedores.
sexta-feira, 30 de novembro de 2012
Reaproveite Senhas de Atendimento com o PostgreSQL
Voltei a ensinar a disciplina de banco de dados e uma dúvida inteligente de um aluno aplicado ajudou a animar o final da última aula. Respondi à dúvida e aparentemente ele ficou satisfeito, mas aproveitei a ideia dele para compor este post. O problema a ser resolvido é manter uma lista de códigos com valores entre 1 e N para serem utilizados por um sistema ou aplicação. Os códigos são reaproveitados, isto é, caso um código não esteja mais disponível, pode ser reutilizado, como por exemplo, no caso de uma senha para atendimento em uma fila. Como manter e tratar este problema com os recursos do banco de dados postgres?

Em primeiro lugar, deixo para os comentários dos interessados maiores discussões sobre as possíveis alternativas. Apresentarei uma solução simples que utiliza triggers, mas espero que a mesma possa ser melhorada e questionada por você, caro leitor.
* Solução de lista de códigos
Permite o controle da utilização e reutilização de códigos através de uma lista com dois campos, um sendo o primeiro o valor do código e outro a indicação de sua utilização ou não.
A lista é armazenada em uma tabela e inicializada na sua criação. Esta lista é atualizada por uma trigger na tabela "usuária" dos códigos. O gatilho atualiza a tabela de código em dois momentos: na utilização de um código e na liberação do código para reuso.
* Tabela de Lista de Códigos
Abaixo, coloco o script da nossa lista de códigos. Coloquei a cláusula UNIQUE para o campo de código para evitar repetições que violassem a integridade da lista e ao tempo gerar um índice implícido para o campo de código, a ser utilizado nas consultas. Vamos inicializar a nossa lista com 10 códigos, inteiros com valor entre 1 e 10, com o valor false, equivalente a "desalocado".
CREATE TABLE lista_codigos (codigo integer UNIQUE, flag_utilizado boolean);
INSERT INTO lista_codigos (codigo, flag_utilizado) VALUES (1,false), (2,false), (3,false), (4,false), (5,false), (6,false), (7,false), (8,false), (9,false), (10,false); --INICIALIZACAO
* Tabela Usuária de Códigos
A tabela em que serão armazenados os códigos utilizados apresentará dois gatilhos, sendo um em caso de inserção de código, e outra para exclusão de código. Adicionei também uma restrição UNIQUE no campo código para não ter de validar tentativas de utilizar o código mais de uma vez.
CREATE TABLE usa_codigos (codigo integer UNIQUE);
Abaixo, os códigos das trigers e trigger functions associadas.
CREATE OR REPLACE FUNCTION pegar_codigo() RETURNS trigger AS $pegar_codigo$
BEGIN
UPDATE lista_codigos SET flag_utilizado = true WHERE codigo = new.codigo;
RETURN new;
END;
$pegar_codigo$ LANGUAGE plpgsql;
CREATE TRIGGER pega_codigo BEFORE INSERT ON usa_codigos FOR EACH ROW EXECUTE PROCEDURE pegar_codigo ();
CREATE OR REPLACE FUNCTION liberar_codigo() RETURNS trigger AS $liberar_codigo$
BEGIN
UPDATE lista_codigos SET flag_utilizado = false WHERE lista_codigos.codigo = old.codigo;
RETURN old;
END;
$liberar_codigo$ LANGUAGE plpgsql;
CREATE TRIGGER libera_codigo AFTER DELETE ON usa_codigos FOR EACH ROW EXECUTE PROCEDURE liberar_codigo ();
* Testes da Lista
CENÁRIO 1: Reservando códigos. Neste cenário, basta inserir um registro na tabela usa_codigos e consultar a tabela lista_codigos para verificar se foram reservados os códigos.
INSERT INTO usa_codigos (codigo) VALUES (1), (3), (4), (9), (10);
O resultado obtido está correto.
SELECT codigo, CASE
WHEN flag_utilizado = true THEN 'SIM'
ELSE 'NÃO'
END AS reservado FROM lista_codigos ORDER BY codigo;
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | SIM
4 | SIM
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | SIM
10 | SIM
(10 registros)
CENÁRIO 2: Liberando códigos. Inicialmente, libero o código 3. A liberação é a exclusão da tabela de códigos.
DELETE FROM usa_codigos WHERE codigo = 3;
O resultado obtido está de acordo com o desejado.
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | NÃO
4 | SIM
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | SIM
10 | SIM
(10 registros)
CENÁRIO 3: Liberando todos os códigos de uma só vez. O resultado corresponde à expectativa.
DELETE FROM usa_codigos;
codigo | reservado
--------+-----------
1 | NÃO
2 | NÃO
3 | NÃO
4 | NÃO
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | NÃO
10 | NÃO
(10 registros)
CENÁRIO 4: Testando reservar código já reservado. A restrição CHECK garante a integridade e o código é reservado, como esperado.
postgres=# INSERT INTO usa_codigos (codigo) VALUES (1);
INSERT 0 1
postgres=# INSERT INTO usa_codigos (codigo) VALUES (1);
ERRO: duplicar valor da chave viola a restrição de unicidade "usa_codigos_codigo_key"
DETALHE: Chave (codigo)=(1) já existe.
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | NÃO
4 | NÃO
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | NÃO
10 | NÃO
(10 registros)
CENÁRIO 5: Testando liberar código já liberado. Não ocorre erro e a alocação dos códigos permanece inalterada. Ao menos neste teste inicial, as operações foram realizadas a contento!
postgres=# DELETE FROM usa_codigos WHERE codigo = 3;
DELETE 0
postgres=# SELECT codigo, CASE
WHEN flag_utilizado = true THEN 'SIM'
ELSE 'NÃO'
END AS reservado FROM lista_codigos ORDER BY codigo;
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | NÃO
4 | NÃO
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | NÃO
10 | NÃO
(10 registros)
* Adicionando Funcionalidades
Podem ser implementadas consultas ou funções que ajudem a emitir as senhas e liberar as senhas para reaproveitamento, além de consultas básicas para:
- Consultar o primeiro código disponível
- Consultar o último código disponível
- Consultar a quantidade de códigos disponíveis
- Consultar a quantidade de códigos não disponíveis
Mas deixo aos leitores estas tarefas como exercício.
* Notas conclusivas
- Uma trigger ou restrição de acesso pode evitar que se utilize a cláusula UPDATE para a tabela de códigos, ou tratar o update, o que eu acho mais trabalhoso!
- Deixo para os leitores a tarefa de implementar esta solução utilizando arrays, e empregando outras formas alternativas e talvez mais eficientes.
Em primeiro lugar, deixo para os comentários dos interessados maiores discussões sobre as possíveis alternativas. Apresentarei uma solução simples que utiliza triggers, mas espero que a mesma possa ser melhorada e questionada por você, caro leitor.
* Solução de lista de códigos
Permite o controle da utilização e reutilização de códigos através de uma lista com dois campos, um sendo o primeiro o valor do código e outro a indicação de sua utilização ou não.
A lista é armazenada em uma tabela e inicializada na sua criação. Esta lista é atualizada por uma trigger na tabela "usuária" dos códigos. O gatilho atualiza a tabela de código em dois momentos: na utilização de um código e na liberação do código para reuso.
* Tabela de Lista de Códigos
Abaixo, coloco o script da nossa lista de códigos. Coloquei a cláusula UNIQUE para o campo de código para evitar repetições que violassem a integridade da lista e ao tempo gerar um índice implícido para o campo de código, a ser utilizado nas consultas. Vamos inicializar a nossa lista com 10 códigos, inteiros com valor entre 1 e 10, com o valor false, equivalente a "desalocado".
CREATE TABLE lista_codigos (codigo integer UNIQUE, flag_utilizado boolean);
INSERT INTO lista_codigos (codigo, flag_utilizado) VALUES (1,false), (2,false), (3,false), (4,false), (5,false), (6,false), (7,false), (8,false), (9,false), (10,false); --INICIALIZACAO
* Tabela Usuária de Códigos
A tabela em que serão armazenados os códigos utilizados apresentará dois gatilhos, sendo um em caso de inserção de código, e outra para exclusão de código. Adicionei também uma restrição UNIQUE no campo código para não ter de validar tentativas de utilizar o código mais de uma vez.
CREATE TABLE usa_codigos (codigo integer UNIQUE);
Abaixo, os códigos das trigers e trigger functions associadas.
CREATE OR REPLACE FUNCTION pegar_codigo() RETURNS trigger AS $pegar_codigo$
BEGIN
UPDATE lista_codigos SET flag_utilizado = true WHERE codigo = new.codigo;
RETURN new;
END;
$pegar_codigo$ LANGUAGE plpgsql;
CREATE TRIGGER pega_codigo BEFORE INSERT ON usa_codigos FOR EACH ROW EXECUTE PROCEDURE pegar_codigo ();
CREATE OR REPLACE FUNCTION liberar_codigo() RETURNS trigger AS $liberar_codigo$
BEGIN
UPDATE lista_codigos SET flag_utilizado = false WHERE lista_codigos.codigo = old.codigo;
RETURN old;
END;
$liberar_codigo$ LANGUAGE plpgsql;
CREATE TRIGGER libera_codigo AFTER DELETE ON usa_codigos FOR EACH ROW EXECUTE PROCEDURE liberar_codigo ();
* Testes da Lista
CENÁRIO 1: Reservando códigos. Neste cenário, basta inserir um registro na tabela usa_codigos e consultar a tabela lista_codigos para verificar se foram reservados os códigos.
INSERT INTO usa_codigos (codigo) VALUES (1), (3), (4), (9), (10);
O resultado obtido está correto.
SELECT codigo, CASE
WHEN flag_utilizado = true THEN 'SIM'
ELSE 'NÃO'
END AS reservado FROM lista_codigos ORDER BY codigo;
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | SIM
4 | SIM
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | SIM
10 | SIM
(10 registros)
CENÁRIO 2: Liberando códigos. Inicialmente, libero o código 3. A liberação é a exclusão da tabela de códigos.
DELETE FROM usa_codigos WHERE codigo = 3;
O resultado obtido está de acordo com o desejado.
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | NÃO
4 | SIM
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | SIM
10 | SIM
(10 registros)
CENÁRIO 3: Liberando todos os códigos de uma só vez. O resultado corresponde à expectativa.
DELETE FROM usa_codigos;
codigo | reservado
--------+-----------
1 | NÃO
2 | NÃO
3 | NÃO
4 | NÃO
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | NÃO
10 | NÃO
(10 registros)
CENÁRIO 4: Testando reservar código já reservado. A restrição CHECK garante a integridade e o código é reservado, como esperado.
postgres=# INSERT INTO usa_codigos (codigo) VALUES (1);
INSERT 0 1
postgres=# INSERT INTO usa_codigos (codigo) VALUES (1);
ERRO: duplicar valor da chave viola a restrição de unicidade "usa_codigos_codigo_key"
DETALHE: Chave (codigo)=(1) já existe.
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | NÃO
4 | NÃO
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | NÃO
10 | NÃO
(10 registros)
CENÁRIO 5: Testando liberar código já liberado. Não ocorre erro e a alocação dos códigos permanece inalterada. Ao menos neste teste inicial, as operações foram realizadas a contento!
postgres=# DELETE FROM usa_codigos WHERE codigo = 3;
DELETE 0
postgres=# SELECT codigo, CASE
WHEN flag_utilizado = true THEN 'SIM'
ELSE 'NÃO'
END AS reservado FROM lista_codigos ORDER BY codigo;
codigo | reservado
--------+-----------
1 | SIM
2 | NÃO
3 | NÃO
4 | NÃO
5 | NÃO
6 | NÃO
7 | NÃO
8 | NÃO
9 | NÃO
10 | NÃO
(10 registros)
* Adicionando Funcionalidades
Podem ser implementadas consultas ou funções que ajudem a emitir as senhas e liberar as senhas para reaproveitamento, além de consultas básicas para:
- Consultar o primeiro código disponível
- Consultar o último código disponível
- Consultar a quantidade de códigos disponíveis
- Consultar a quantidade de códigos não disponíveis
Mas deixo aos leitores estas tarefas como exercício.
* Notas conclusivas
- Uma trigger ou restrição de acesso pode evitar que se utilize a cláusula UPDATE para a tabela de códigos, ou tratar o update, o que eu acho mais trabalhoso!
- Deixo para os leitores a tarefa de implementar esta solução utilizando arrays, e empregando outras formas alternativas e talvez mais eficientes.
segunda-feira, 26 de novembro de 2012
Recuperando Informações de Sessão no PostgreSQL
Qual é o banco de dados corrente? E qual o usuário corrente? Qual é exatamente a versão do postgres que estamos utilizando? Estas informações são úteis para se poder trabalhar com bancos de dados, e são fornecidas por funções informacionais de sessão. Vamos apresentar neste post uma listagem com as funções disponibilizadas no postgres e alguns exemplos de utilização:
| current_database() | name | Nome do banco de dados corrente. |
| current_schema() | name | Nome do esquema corrente. |
| current_schemas(boolean) | name[] | Nomes dos esquemas no caminho de procura incluindo, opcionalmente, os esquemas implícitos. |
| current_user | name | Nome do usuário do contexto de execução corrente. |
| inet_client_addr() | inet | Endereço da conexão remota. |
| inet_client_port() | int4 | Porta da conexão remota. |
| inet_server_addr() | inet | Endereço da conexão local. |
| inet_server_port() | int4 | Porta da conexão local. |
| session_user | name | Nome do usuário da sessão. |
| user | name | Equivalente à função "current_user" |
| version() | text | Informações relativas à versão corrente do PostgreSQL |
* Banco de dados e Esquema
Para recuperar informações de banco de dados e esquema, utilizam-se as funções current_database(), current_schema() e current_schemas(boolean).
Exemplo 1: Dados dos esquemas.
postgres=# SELECT current_database(), current_schema();
current_database | current_schema
------------------+----------------
postgres | public
(1 registro)
current_database | current_schema
------------------+----------------
postgres | public
(1 registro)
Exemplo 2: Caminho de procura com e sem os esquemas implícitos.
postgres=# SELECT current_schemas(true) as SCHEMAS_TODOS, current_schemas(false) AS SCHEMAS_EXPLICITOS;
schemas_todos | schemas_explicitos
---------------------+--------------------
{pg_catalog,public} | {public}
(1 registro)
schemas_todos | schemas_explicitos
---------------------+--------------------
{pg_catalog,public} | {public}
(1 registro)
* Informações de Conexão
Permitem a recuperação dedados sobre os servidores e clientes utilizados na conexão, e as portas de comunicação utilizadas. Funções: inet_client_addr(), inet_client_port(), inet_server_addr() e inet_server_port().
Exemplo 3: Informações da conexão corrente.
postgres=# SELECT inet_client_addr(), inet_client_port(), inet_server_addr(), inet_server_port();
inet_client_addr | inet_client_port | inet_server_addr | inet_server_port
------------------+------------------+------------------+------------------
| | |
(1 registro)
inet_client_addr | inet_client_port | inet_server_addr | inet_server_port
------------------+------------------+------------------+------------------
| | |
(1 registro)
* Dados do usuário da sessão.
São consultados com as funções sem parênteses current_user, session_user e user.
Exemplo 4: Dados do usuário e mudança de usuário.
postgres=# SELECT current_user, session_user, user;
current_user | session_user | current_user
--------------+--------------+--------------
postgres | postgres | postgres
(1 registro)
postgres=# SET SESSION AUTHORIZATION 'user1';
SET
postgres=> SELECT current_user, session_user, user;
current_user | session_user | current_user
--------------+--------------+--------------
user1 | user1 | user1
(1 registro)
current_user | session_user | current_user
--------------+--------------+--------------
postgres | postgres | postgres
(1 registro)
postgres=# SET SESSION AUTHORIZATION 'user1';
SET
postgres=> SELECT current_user, session_user, user;
current_user | session_user | current_user
--------------+--------------+--------------
user1 | user1 | user1
(1 registro)
* Versão do PostgreSQL
Exemplo 5: Consulta à versão do postgresql.
postgres=# SELECT version();
version ---------------------------------------------------------------------------------------------------------
PostgreSQL 9.2.1 on i686-pc-linux-gnu, compiled by gcc-4.4.real (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3, 32-bit
(1 registro)
* Recuperando todos os dados da sessão
Exemplo 6: Consulta a todas as informações de sessão:
postgres=# SELECT 'BANCO : ' || current_database() AS INFO UNION SELECT 'ESQUEMA : ' || current_schema() AS INFO UNION
SELECT 'ESQUEMAS : ' || CAST(current_schemas(true) AS VARCHAR) AS INFO UNION
SELECT 'USUARIO : ' || current_user AS INFO UNION
SELECT 'SES. USR.: ' || session_user AS INFO UNION
SELECT 'USER : ' || user AS INFO UNION
SELECT 'CLI. ADR.: ' || inet_client_addr() AS INFO UNION
SELECT 'CLI. POR.: ' || inet_client_port() AS INFO UNION
SELECT 'SER. ADR.: ' || inet_server_addr() AS INFO UNION
SELECT 'SER. POR.: ' || inet_server_port() AS INFO UNION
SELECT 'VERSAO : ' || version() AS INFO;
info --------------------------------------------------------------------------------------------------------------------
ESQUEMAS : {pg_catalog,public}
ESQUEMA : public
USER : postgres
SES. USR.: postgres
USUARIO : postgres
VERSAO : PostgreSQL 9.2.1 on i686-pc-linux-gnu, compiled by gcc-4.4.real (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3, 32-bit
BANCO : postgres
(8 registros)
quarta-feira, 14 de novembro de 2012

{kind=link}
{kind=link}
{kind=link}
Assinar:
Postagens (Atom)