Depois do teste de softwares em versões beta, a versão Release Candidate é a mais próxima da versão oficial. A poucos minutos a versão RC do PostgreSQL 8.4 foi liberada para download aqui!
Lembro que esta não é uma versão definitiva e não deve ser utilizada em sistemas de produção, mas pode ser utilizada, por exemplo, para o desenvolvimento de produtos enquanto a oficial não chega de fato. Teste e compartilhe suas primeiras impressões!
terça-feira, 16 de junho de 2009
segunda-feira, 15 de junho de 2009
Enquete: Que Prioridades o Desenvolvimento do Postgres deve Assumir?
Que Prioridades o Desenvolvimento do Postgres deve Assumir? Você já pensou nisso?
Essa enquete (What's your highest priority for PostgreSQL development?) está disponível no site da comunidade internacional do PostgreSQL. Se você tem alguma prioridade que não está na lista, podes coloca-l a como comentário.
Fazer acesso à enquete!
Essa enquete (What's your highest priority for PostgreSQL development?) está disponível no site da comunidade internacional do PostgreSQL. Se você tem alguma prioridade que não está na lista, podes coloca-l a como comentário.
Fazer acesso à enquete!
quarta-feira, 10 de junho de 2009
Números Aleatórios com o PostgreSQL: A Função RANDOM()
Gerar números aleatórios é uma necessidade importante para a geração de grandes bases de dados de teste. Para maior veracidade nos testes, uma certa aleatoriedade é esperada deste tipo de base de dados. Aí entram em cena as rotinas de geração de números aleatórios.
A função RANDOM() é o método nativo do PostgreSQL para a geração de seqüências de números aleatórios. Neste post vamos apresentar exemplos práticos do uso desta função que podem ser úteis no cotidiano.
Ao se executar a função RANDOM(), é retornado um número aleatório entre zero e 1 com muitas casas decimais. Dependendo da necessidade, pode-se gerar um número positivo, um valor dentro de um determinado determinado intervalo. Valores e intervalos podem assumir valores nulos e negativos com pequenas variações de sintaxe.
* Sintaxe
1 - A sintaxe básica.
SELECT random();
Retorna: 0.896639783866704, 0.516120770014822...
2 - Busca de números com um valor dentro de um intervalo começado com zero é um pouco mais complicada. O exemplo abaixo retorna um valor entre 0 e 99. Para aumentar ou diminuir o intervalo, trocar o número 100 por outro valor. Ajustar as casas decimais do comando CAST se desejar valores fracionários. A função ROUND() elimina decimais indesejadas.
SELECT round(CAST (random()*100 AS NUMERIC),0);
3 - Busca de números com um valor dentro de um intervalo qualquer demanda atenção. O exemplo abaixo retorna um valor entre 27 e 90. Para aumentar ou diminuir o intervalo, trocar os números 27 e 91 por outros valores. Ajustar as casas decimais do comando CAST se desejar valores fracionários.
SELECT 27 + round(CAST (random()*(91-27) AS NUMERIC),0);
4 - Busca de números com um valor dentro de um intervalo começado com valor negativo. Bastante similar ao exemplo anterior.
SELECT -57 + round(CAST (random()*(91+57) AS NUMERIC),0);
A função RANDOM() é o método nativo do PostgreSQL para a geração de seqüências de números aleatórios. Neste post vamos apresentar exemplos práticos do uso desta função que podem ser úteis no cotidiano.
Ao se executar a função RANDOM(), é retornado um número aleatório entre zero e 1 com muitas casas decimais. Dependendo da necessidade, pode-se gerar um número positivo, um valor dentro de um determinado determinado intervalo. Valores e intervalos podem assumir valores nulos e negativos com pequenas variações de sintaxe.
* Sintaxe
1 - A sintaxe básica.
SELECT random();
Retorna: 0.896639783866704, 0.516120770014822...
2 - Busca de números com um valor dentro de um intervalo começado com zero é um pouco mais complicada. O exemplo abaixo retorna um valor entre 0 e 99. Para aumentar ou diminuir o intervalo, trocar o número 100 por outro valor. Ajustar as casas decimais do comando CAST se desejar valores fracionários. A função ROUND() elimina decimais indesejadas.
SELECT round(CAST (random()*100 AS NUMERIC),0);
3 - Busca de números com um valor dentro de um intervalo qualquer demanda atenção. O exemplo abaixo retorna um valor entre 27 e 90. Para aumentar ou diminuir o intervalo, trocar os números 27 e 91 por outros valores. Ajustar as casas decimais do comando CAST se desejar valores fracionários.
SELECT 27 + round(CAST (random()*(91-27) AS NUMERIC),0);
4 - Busca de números com um valor dentro de um intervalo começado com valor negativo. Bastante similar ao exemplo anterior.
SELECT -57 + round(CAST (random()*(91+57) AS NUMERIC),0);
quarta-feira, 3 de junho de 2009
Geração de CPFs Fictícios com Pl/ PgSQL
A geração de massas de dados para teste é um processo muito importante, para verificar o comportamento de um banco de dados em relação à carga de processamento que o mesmo tem de desempenhar. A geração de CPFs fictícios é uma atividade relativamente comum em empresas brasileiras que armazenam este tipo de identificador. No entanto muitas vezes os testes são feitos com valores incorretos, isto é, que não respeitam as regras para os dois dígitos verificadores.
Abaixo está um código que se propõe a retornar CPFs aleatórios com dígitos verificadores corretos, implementado em Pl/ PgSQL.
Os comandos mais importantes deste código são:
- Random() - Geração de números aleatórios
- substring() - Extração de parte de uma string com base nso parâmetros fornecidos
- CAST () - Conversão de tipos no PostgreSQL
- trim() - Eliminação de espaços em branco de strings
Os testes foram muito positivos. Coloco para você, leitor, as seguintes perguntas:
- Este código segue um algoritmo correto?
- Ele pode ser melhorado? De que forma?
CREATE OR REPLACE FUNCTION gerar_CPF() RETURNS varchar AS $$
-- ROTINA DE GERAÇÃO DE CPF SEM LOOP
-- Retorna string com CPF aletório correto.
DECLARE
vet_cpf integer [11]; --Recebe o CPF
soma integer; -- Soma utilizada para o cálculo do DV
rest integer; -- Resto da divisão
BEGIN
-- Atribuição dos valores do Vetor
vet_cpf[0] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[1] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[2] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[3] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[4] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[5] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[6] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[7] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[8] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
-- CÁLCULO DO PRIMEIRO NÚMERO DO DV
-- Soma dos nove primeiros multiplicados por 10, 9, 8 e assim por diante...
soma:=(vet_cpf[0]*10)+(vet_cpf[1]*9)+(vet_cpf[2]*8)+(vet_cpf[3]*7)+(vet_cpf[4]*6)+(vet_cpf[5]*5)+(vet_cpf[6]*4)+(vet_cpf[7]*3)+(vet_cpf[8]*2);
rest:=soma % 11;
if (rest = 0) or (rest = 1) THEN
vet_cpf[9]:=0;
ELSE vet_cpf[9]:=(11-rest); END IF;
-- CÁLCULO DO SEGUNDO NÚMERO DO DV
-- Soma dos nove primeiros multiplicados por 11, 10, 9 e assim por diante...
soma:= (vet_cpf[0]*11) + (vet_cpf[1]*10) + (vet_cpf[2]*9) + (vet_cpf[3]*8) + (vet_cpf[4]*7) + (vet_cpf[5]*6) + (vet_cpf[6]*5) + (vet_cpf[7]*4) + (vet_cpf[8]*3) + (vet_cpf[9]*2);
rest:=soma % 11;
if (rest = 0) or (rest = 1) THEN
vet_cpf[10] := 0;
ELSE
vet_cpf[10] := (11-rest);
END IF;
--Retorno do CPF
RETURN trim(trim(to_char(vet_cpf[0],'9')) || trim(to_char(vet_cpf[1],'9')) || trim(to_char(vet_cpf[2],'9')) || trim(to_char(vet_cpf[3],'9')) || trim(to_char(vet_cpf[4],'9')) || trim(to_char(vet_cpf[5],'9')) || trim(to_char(vet_cpf[6],'9')) || trim(to_char(vet_cpf[7],'9'))|| trim(to_char(vet_cpf[8],'9')) || trim(to_char(vet_cpf[9],'9')) || trim(to_char(vet_cpf[10],'9')));
END;
$$ LANGUAGE PLPGSQL;
Chamada da função, retornando um CPF aleatório.
select gerar_CPF() ;
A função para fazer o teste está neste post. O resultado para um CPF correto é 1.
select CPF_Validar_Sem_Loop(gerar_CPF());
select CPF_Validar_Sem_Loop('66067526557'); --Gerado pelo programa
Abaixo está um código que se propõe a retornar CPFs aleatórios com dígitos verificadores corretos, implementado em Pl/ PgSQL.
Os comandos mais importantes deste código são:
- Random() - Geração de números aleatórios
- substring() - Extração de parte de uma string com base nso parâmetros fornecidos
- CAST () - Conversão de tipos no PostgreSQL
- trim() - Eliminação de espaços em branco de strings
Os testes foram muito positivos. Coloco para você, leitor, as seguintes perguntas:
- Este código segue um algoritmo correto?
- Ele pode ser melhorado? De que forma?
CREATE OR REPLACE FUNCTION gerar_CPF() RETURNS varchar AS $$
-- ROTINA DE GERAÇÃO DE CPF SEM LOOP
-- Retorna string com CPF aletório correto.
DECLARE
vet_cpf integer [11]; --Recebe o CPF
soma integer; -- Soma utilizada para o cálculo do DV
rest integer; -- Resto da divisão
BEGIN
-- Atribuição dos valores do Vetor
vet_cpf[0] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[1] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[2] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[3] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[4] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[5] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[6] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[7] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
vet_cpf[8] := cast(substring (CAST (random() AS VARCHAR), 3,1) as integer);
-- CÁLCULO DO PRIMEIRO NÚMERO DO DV
-- Soma dos nove primeiros multiplicados por 10, 9, 8 e assim por diante...
soma:=(vet_cpf[0]*10)+(vet_cpf[1]*9)+(vet_cpf[2]*8)+(vet_cpf[3]*7)+(vet_cpf[4]*6)+(vet_cpf[5]*5)+(vet_cpf[6]*4)+(vet_cpf[7]*3)+(vet_cpf[8]*2);
rest:=soma % 11;
if (rest = 0) or (rest = 1) THEN
vet_cpf[9]:=0;
ELSE vet_cpf[9]:=(11-rest); END IF;
-- CÁLCULO DO SEGUNDO NÚMERO DO DV
-- Soma dos nove primeiros multiplicados por 11, 10, 9 e assim por diante...
soma:= (vet_cpf[0]*11) + (vet_cpf[1]*10) + (vet_cpf[2]*9) + (vet_cpf[3]*8) + (vet_cpf[4]*7) + (vet_cpf[5]*6) + (vet_cpf[6]*5) + (vet_cpf[7]*4) + (vet_cpf[8]*3) + (vet_cpf[9]*2);
rest:=soma % 11;
if (rest = 0) or (rest = 1) THEN
vet_cpf[10] := 0;
ELSE
vet_cpf[10] := (11-rest);
END IF;
--Retorno do CPF
RETURN trim(trim(to_char(vet_cpf[0],'9')) || trim(to_char(vet_cpf[1],'9')) || trim(to_char(vet_cpf[2],'9')) || trim(to_char(vet_cpf[3],'9')) || trim(to_char(vet_cpf[4],'9')) || trim(to_char(vet_cpf[5],'9')) || trim(to_char(vet_cpf[6],'9')) || trim(to_char(vet_cpf[7],'9'))|| trim(to_char(vet_cpf[8],'9')) || trim(to_char(vet_cpf[9],'9')) || trim(to_char(vet_cpf[10],'9')));
END;
$$ LANGUAGE PLPGSQL;
Chamada da função, retornando um CPF aleatório.
select gerar_CPF() ;
A função para fazer o teste está neste post. O resultado para um CPF correto é 1.
select CPF_Validar_Sem_Loop(gerar_CPF());
select CPF_Validar_Sem_Loop('66067526557'); --Gerado pelo programa
quarta-feira, 13 de maio de 2009
PostgreSQL no IV Festival Software Livre da Bahia
Eventos de software livre ganham maior relevância, à medida em que se consolidam. O III ENSL - Encontro Nordestino de Software Livre e o IV Festival Software Livre da Bahia, que antes eram iniciativas distintas, se fundiram em um único evento que será realizado nos dias 29 e 30 de maio de 2009, no campus da Universidade Estadual da Bahia (UNEB), em Salvador.
A programação é vasta e eclética e abrange cinco grandes áreas: Cultura Digital Livre; Casos de Sucesso; Ferramentas e Soluções; Desenvolvimento de Software e Educação e Inclusão Digital.
O PostgreSQL será discutido na palestra "Tuning de Banco de Dados Livre: O Caso do PostgreSQL", ministrada por mim.
A programação detalhada e as inscrições estão disponíveis até 24/05 no site do evento!
A programação é vasta e eclética e abrange cinco grandes áreas: Cultura Digital Livre; Casos de Sucesso; Ferramentas e Soluções; Desenvolvimento de Software e Educação e Inclusão Digital.
O PostgreSQL será discutido na palestra "Tuning de Banco de Dados Livre: O Caso do PostgreSQL", ministrada por mim.
A programação detalhada e as inscrições estão disponíveis até 24/05 no site do evento!
terça-feira, 28 de abril de 2009
A Oracle comprou a SUN e conseqüentemente o Java e o MySQL. E como fica o PostgreSQL?
A Oracle comprou a SUN e conseqüentemente o Java e o MySQL. Mais informações podem ser obtidas aqui. Que impactos esta aquisição causará sobre o PostgreSQL?
Ainda é muito cedo para ter certezas sobre este tema, mas ele certamente é bastante crítico para a área de banco de dados. A Oracle adquiriu nos últimos anos uma série de empresas e seus softwares de banco, dentre elas o Berkeley DB, que passaram a figurar entre as soluções desta empresa. As novas aquisições continuarão a ser livres e a serem aprimoradas? O suporte do java ao PostgreSQL estará ameaçado? O espaço para o PostgreSQL diminuirá ou será ampliado? Estas e outras questões permanecem em aberto.
Baseado nestas dúvidas tive a idéia de criar um tópico aberto. Peço que coloquem opiniões e links para reportagens sobre o impacto desta aquisição para a comunidade de banco de dados e particularmente para os usuários do PostgreSQL.
Atualização (13/05/2009): anexo link para posts sobre o assunto no site do Fernando Ike e do Telles.
Ainda é muito cedo para ter certezas sobre este tema, mas ele certamente é bastante crítico para a área de banco de dados. A Oracle adquiriu nos últimos anos uma série de empresas e seus softwares de banco, dentre elas o Berkeley DB, que passaram a figurar entre as soluções desta empresa. As novas aquisições continuarão a ser livres e a serem aprimoradas? O suporte do java ao PostgreSQL estará ameaçado? O espaço para o PostgreSQL diminuirá ou será ampliado? Estas e outras questões permanecem em aberto.
Baseado nestas dúvidas tive a idéia de criar um tópico aberto. Peço que coloquem opiniões e links para reportagens sobre o impacto desta aquisição para a comunidade de banco de dados e particularmente para os usuários do PostgreSQL.
Atualização (13/05/2009): anexo link para posts sobre o assunto no site do Fernando Ike e do Telles.
quinta-feira, 16 de abril de 2009
Versão 8.4: primeira release beta disponível!
O grupo de desenvolvimento do PostgreSQL anunciou que a primeira versão 8.4 BETA está disponível para download. A colaboração da comunidade nos testes é de vital importância para o diagnóstico e correção de quaisquer problemas na ferramenta. Esta versão não deve ser utilizada para aplicações corporativas, por ser menos estável que as releases padrão.
Testemos, critiquemos e participemos!!!
Mais informações em: http://www.postgresql.org/developer/beta.
Em breve apresentaremos um detalhamento das novas funcionalidades da versão 8.4 neste espaço.
Testemos, critiquemos e participemos!!!
Mais informações em: http://www.postgresql.org/developer/beta.
Em breve apresentaremos um detalhamento das novas funcionalidades da versão 8.4 neste espaço.
quarta-feira, 8 de abril de 2009
Fique Atualizado em PostgreSQL com o Addict-o-matic!!!
Ficar atualizado em tecnologias de hardware e software não é das tarefas mais fáceis. O site Addict-o-matic faz a coleta de uma série de notícias, posts em blogs, vídeos e imagens em uma série de fontes na rede. O resultado de uma pesquisa sobre o PostgreSQL não decepcionou.
Clique aqui para experimentar! Podem ser fornecidas várias opções de pesquisa, e o site funciona bem como agregador de informações.
A dica do site foi do blog da colunista Sandra Carvalho.
Clique aqui para experimentar! Podem ser fornecidas várias opções de pesquisa, e o site funciona bem como agregador de informações.
A dica do site foi do blog da colunista Sandra Carvalho.
sexta-feira, 3 de abril de 2009
Ano Bissexto no PostgreSQL!
Às vezes o mais difícil de fazer são coisas realmente simples. Os exemplo de código abaixo são implementações de uma rotina que calcula se um ano é bissexto ou não.
Segundo a Wikipedia, as regras do ano bissexto são poucas, mas não são triviais:
* São bissextos todos os anos múltiplos de 400, p.ex: 1600, 2000, 2400, 2800
* Não são bissextos todos os múltiplos de 100 e não de 400, p.ex: 1700, 1800, 1900, 2100, 2200, 2300, 2500...
* São bissextos todos os múltiplos de 4 e não múltiplos de 100, p.ex: 1996, 2004, 2008, 2012, 2016...
* Não são bissextos todos os demais anos.
Com base no que é apresentado neste post, peço que você que me responda três perguntas:
- Os dois exemplos abaixo estão corretos?
- Qual dos dois apresentaria alguma vantagem em relação ao outro? Ou são ambos equivalentes?
- É possível melhorar as implementações? De que formas?
As duas funções criadas retornam 1 se ano for bissexto, 0 se não for e 99 se for anterior a 1582, para anos acima de 1582.
Exemplo 1:
CREATE OR REPLACE FUNCTION ano_bissexto (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=0; --Inicialização
IF ($1%400=0) THEN
ret:=1; /*Bissexto*/
ELSE
IF ($1%4=0) AND ($1%100<>0) THEN
ret:=1; /*Bissexto*/
END IF;
END IF;
RETURN ret;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto(1600);
Exemplo 2:
CREATE OR REPLACE FUNCTION ano_bissexto_menor (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=$1; --Inicialização
IF (ret%100=0) THEN
ret:=ret/100;
END IF;
IF ret%4=0 THEN
RETURN 1; --Bissexto
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto_menor(1600);
Segundo a Wikipedia, as regras do ano bissexto são poucas, mas não são triviais:
* São bissextos todos os anos múltiplos de 400, p.ex: 1600, 2000, 2400, 2800
* Não são bissextos todos os múltiplos de 100 e não de 400, p.ex: 1700, 1800, 1900, 2100, 2200, 2300, 2500...
* São bissextos todos os múltiplos de 4 e não múltiplos de 100, p.ex: 1996, 2004, 2008, 2012, 2016...
* Não são bissextos todos os demais anos.
Com base no que é apresentado neste post, peço que você que me responda três perguntas:
- Os dois exemplos abaixo estão corretos?
- Qual dos dois apresentaria alguma vantagem em relação ao outro? Ou são ambos equivalentes?
- É possível melhorar as implementações? De que formas?
As duas funções criadas retornam 1 se ano for bissexto, 0 se não for e 99 se for anterior a 1582, para anos acima de 1582.
Exemplo 1:
CREATE OR REPLACE FUNCTION ano_bissexto (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=0; --Inicialização
IF ($1%400=0) THEN
ret:=1; /*Bissexto*/
ELSE
IF ($1%4=0) AND ($1%100<>0) THEN
ret:=1; /*Bissexto*/
END IF;
END IF;
RETURN ret;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto(1600);
Exemplo 2:
CREATE OR REPLACE FUNCTION ano_bissexto_menor (pAno integer) RETURNS integer AS $$
DECLARE
ret integer;
BEGIN
IF $1<1582 THEN RETURN 99; END IF;
ret :=$1; --Inicialização
IF (ret%100=0) THEN
ret:=ret/100;
END IF;
IF ret%4=0 THEN
RETURN 1; --Bissexto
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql;
SELECT ano_bissexto_menor(1600);
quinta-feira, 2 de abril de 2009
Enquete Encerrada: PostgreSQL é um Ótimo Nome para Banco de Dados!
A enquete que perguntava a respeito do nome do PostgreSQL foi encerrada, e foi considerado que o nome tradicional deve ser mantido por uma maioria esmagadora. Os nomes alternativos sugeridos não tiveram aceitação e a opção de outros nomes não foi acolhida. Abaixo, os dados:

| Opção | Votos | Percentual |
| Deve ser mantido. | 152 | 69,72 |
| Que tal PgDB? | 15 | 6,88 |
| Postgree seria melhor | 35 | 16,06 |
| Outro | 9 | 4,13 |
| Não sei. | 7 | 3,21 |
| Totais | 218 | 100 |
Concorda com o resultado? Discorda? Deixe seu comentário!

sexta-feira, 27 de março de 2009
Log com Arquivos CSV
Arquivos texto são muito utilizados em sistemas de informação. No entanto, sua manipulação automática muitas vezes é difícil por serem meios não estruturados de armazenamento de informações. O uso de arquivos CSV (Comma-Separated-Values - arquivos com valores separados por vírgula) facilita a utilização de arquivos texto para o armazenamento de dados. Um dos usos de arquivos CSV é no armazenamento do log de bancos de dados PostgreSQL, que passa a ser mais facilmente tratado por meio de planilhas eletrônicas, que apresentam os itens do log de forma tabular.
A utilização de log em arquivo CSV é muito simples, bastando se alterar o arquivo POSTGRESQL.CONF, alterando o parâmetro log_destination, e fazer o reload da configuração. Comente o valor anterior do parâmetro e coloque esta linha:
log_destination = 'csvlog'
A partir deste momento os arquivos de log criados serão do tipo CSV. Abaixo, uma imagem ilustrando como fica armazenado fisicamente o log:
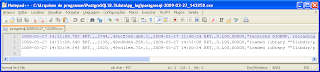
A utilização de log em arquivo CSV é muito simples, bastando se alterar o arquivo POSTGRESQL.CONF, alterando o parâmetro log_destination, e fazer o reload da configuração. Comente o valor anterior do parâmetro e coloque esta linha:
log_destination = 'csvlog'
A partir deste momento os arquivos de log criados serão do tipo CSV. Abaixo, uma imagem ilustrando como fica armazenado fisicamente o log:

segunda-feira, 16 de março de 2009
Que linguagem você utiliza com o PostgreSQL?
Que linguagem você utiliza com o PostgreSQL? Esta é a enquete atual do site do PostgreSQL. Participe!
www.postgresql.org/community
www.postgresql.org/community
Assinar:
Postagens (Atom)